Databricks! What is it?
Databricks is a cloud data platform that aims to help address as companies have started to collect large amounts of data from many unique or different sources, there opens a need to have a single system to store and secondly making sounds, images and other unstructured data accessible for training ML models that requires a different architecture approach; welcome to the world of Databricks as a data platform or whatever you want to call it. In order to understand, we need first understand why and how systems gathered enterprise data.
ETL stands for Extract-Transform-Load, it usually involves moving data from one or more sources, making some changes, and then loading it into a new single destination. In most companies data tends to be silos, stored in various formats and often inaccurate or inconsistent. Most ML algorithms require large amounts of training data in order to produce models that can make accurate predictions. They also require good quality training data and importantly what problem to solve for represents the solution
The following is well known as a hierarchy of needs in the DS. community and is inspired by ‘Maslow’s hierarchy of needs’.
Define common ML terms
Describe examples of products that use ML and general methods of ML problem-solving used in each
Identify whether to solve a problem with ML
Compare and contrast ML to other programming methods
Apply hypothesis testing and the scientific method to ML problems
Have conversations about ML problem-solving methods

For example, your an online retailer that uses a Customer Relationship Management (CRM) system such as SalesForce to keep track of your registered customers. You also use a payment processor such as Stripe to handle and store details of sales transactions made via your e-commerce website. Suppose your goal is to improve your conversion rate by using data about what your customers purchased historically, to make better product recommendations when they are browsing your website. You could certainly use an ML model to power a recommendation engine to achieve this goal. But the challenge is that the data you need is sitting in two different systems. The solution in our case is to use an ETL process to extract, transform and combine them into a data warehouse:
1. Extract — this part of the process involves retrieving data from our two sources, SalesForce and Stripe. Once the data has been retrieved, the ETL tool will load it into a staging area in preparation for the next step.
2. Transform — this is a critical step, because it handles the specifics of how our data will be integrated. Any cleansing, reformatting, deduplication, and blending of data happens here before it can move further down the pipeline.
In our case, let’s say in one system a customer record is stored with the name “K. Reeves”, in another system that same customer record is stored against the name “Keanu Reeves”.
Assume we know it’s the same customer (based on their address zipcode), but the system still needs to reconcile the two, so we don’t end up with duplicate records. ETL frameworks and tools provide us with the logic needed to automate this sort of transformation, and can cater for many other scenarios too.
3. Load — involves successfully inserting the incoming data into the target database, data store, or in our case a data warehouse. We have collected our data, integrated it using an ETL pipeline and loaded it somewhere that is accessible for data science teams.
Common challenges are data accuracy(Data accuracy testing can help spot inconsistencies and duplicates, and monitoring features can help identify instances where you are dealing with incompatible data types and other data management issues), scaling( you should ensure that the ETL tool you choose has the ability to scale to not just your current but also future needs ~ amount of data businesses produce is only expected to grow — 175 Zettabytes by 2025 according to industry top company report, and different sources from which data is collected(Some of this data is best transformed in batches, while for others, streaming, continuous data transformation works better).
Very interesting ETL tool decision tree for start ups is enclosed:

Coming back to evolution of data by enlarge!
Data warehouses were designed to bring together disparate data sources across the organization.
The concept of a data warehouse is nothing new having been around since the late 1980's. The idea was that the data from your operational systems would flow into your data warehouse to support business decision making.
Fast forward a few decades:
There’s usually no built in capabilities for supporting ML use cases — that is the ability to ask more predictive questions using data. Secondly they lack flexibility and scalability when it comes to storing and retrieving new, complex and unstructured data formats.
Modern Cloud Data Warehouses (CDWs) like Snowflake and Redshift have helped to address the ‘scalability’ limitations of on-premise offerings. Product features like BQML in BigQuery are also beginning to cater for the lack of built in ML capabilities in data warehouses.
But they still don’t solve the problem of how to store, manage and get insight from the sheer variety of data types out there today.


Data lake provide a way for storing large amounts of structured, semi-structured, and unstructured data in their raw formats. They were historically built with commodity hardware (storage and compute), used in combination with some sort of distributed processing framework such as Hadoop. The problem is that data lakes have a tendency to become a dumping yard, because they:
Lack the functionality to easily curate and govern the data stored in them; some folks even refer to them as ‘data swamps’!Don’t support the concept of a transaction or enforce any sort of data quality standards.
Enter the Data Lakehouse
Metadata layers for data lakes — this is a way to track things like table versions, descriptions of what the data is and enforce data validation standards. Secondly new query engine designs providing high-performance SQL execution on data lakes, for example Apache Spark. Thirdly, optimize access for data science and machine learning tools — this is making processed data available in open data formats suitable for ML, enabling faster experimentation and development of models.
Databricks is intended to implement the Data Lakehouse concept, in a single unified, cloud based platform.
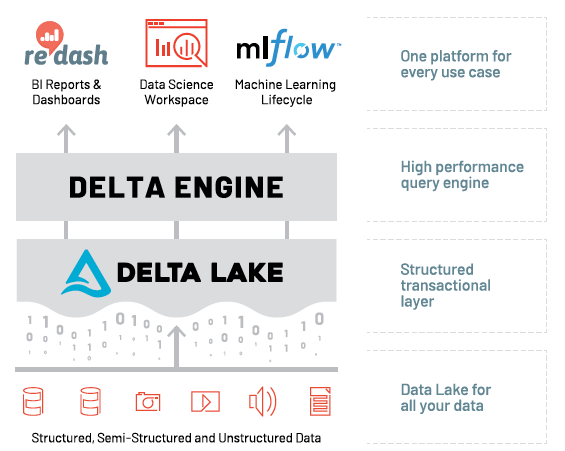
Databricks sits on top of your existing data lake, it can also connect to a variety of popular cloud storage offerings such as AWS S3 and Google Cloud Storage.
Breaking down the layers in the Databricks data platform architecture:
Delta Lake is a storage layer that brings reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of your existing data lake and is fully compatible with Apache Spark APIs.Delta Engine is an optimized query engine for efficiently processing the data stored in the Delta Lake.
Then there are several built in tools available to support Data Science, BI Reporting and ML-Ops.
All the above components are tightly integrated and accessed from a single ‘Workspace’ user interface (UI) that can be hosted on the cloud of your choice — more on that in the next section!
Getting up and running
I always try to ‘walk the walk’, so I decided to give Databricks a spin as part of my research for this post…
Databricks offers a free 14-day trial of it’s platform that you can run on your cloud. I used Google Cloud Platform (GCP) because I’m most familiar with it, but it’s also available on AWS and Azure.
Setup was straightforward, a quick search for ‘Databricks’ in the GCP Marketplace brought me to a page where I could sign up for the trial.
Once the trial ‘subscription’ is complete, you then get a link from the Databricks menu item in GCP to manage setup on a Databricks hosted account management page.


The next step is to create a ‘Workspace’, it’s the environment accessing your assets and doing work on Databricks. You do this via the external Databricks Web Application, which is essentially your control plane.


The Databricks trial only covers you for the use of their platform, you still have to foot the bill for any cloud resources consumed as a result of creating a Workspace and running any jobs.


The first thing you might want to do is Create Table in the Delta Lake by either uploading a file, connecting to supported data sources or using a partner integration.


Next, in order to create a Delta Engine job, or run a Notebook to analyze your data, you will need to create a ‘Cluster’. A Databricks cluster is a set of computation resources and configurations on which you run data engineering, data science, and data analytics workloads.


Machine learning on Databricks

From here we can:
Create Notebooks,use AutoML or
Manage experiments, feature stores, and trained models
I decided to give their AutoML capability a whirl using the ‘Diamonds’ sample dataset that gets created if you run the ‘Quickstart Tutorial Notebook’.
You’ll have to either edit and restart the cluster you previously created to be one that uses the ‘Databricks Runtime for ML’, or create a new one. Other than that the experiment configuration is pretty straightforward — choose the ML problem type (at the time of writing this was either Classification or Regression), your Dataset, Prediction Target and off you go.


Some AutoML tools I have used can be a bit of a ‘black box’ in that you have no idea what detailed steps, such as data processing went on in the background.


Databricks automatically generates a data exploration Notebook articulating the preparation steps such as data profiling, missing values and correlations. I thought this was pretty neat.


As the experiment progresses, details of different training runs are added to the table, including the models used and specific parameters.
Similarly to the data exploration step, you can also dive into the Notebook that represents a particular run. It will show all the steps followed to build the model, it even includes the use of libraries such as SHAP to highlight variable importance.
Costs:
For me the costs of Databricks didn’t really stack up when I compared them to already very strong and integrated user experiences for Data Science and ML in GCP such as Vertex AI. Then again not everyone uses GCP.
Databricks is not server-less and has no ‘fully managed’ option, so the barrier to entry is relatively higher compared to native products on some cloud platforms. But I suppose this is the price for being cloud agnostic.
Overall:
Databricks is a truly unified experience from the Data Lake to Analysis and ML . The cost of entry is high, but it does offer a cloud agnostic solution to an age-old problem. It is also well suited to those wanting to transition from a more traditional Spark environment given its roots in that ecosystem.
I hope you find this article useful as it is for me finding out facts about this.


Comments
Post a Comment